Support Vector Machines explained
Published Nov 26, 2022
Disclaimer: this does not aim to fully cover the possibilities of SVM models. It merely describes the basic concepts related to them. Some details are skipped on purpose with the intention of keeping it short.
You can find a from scratch implementation of an SVM in Julia here: https://github.com/shilangyu/SVM-from-scratch
Invented by Vladimir Vapnik. SVM is a binary linear classifier for supervised learning (though, can be used for regression as well). Input data are points in Euclidean space.
Let be a dataset which is a set of pairs where is a data point in some -dimensional space and is a label of the appropriate data point classifying it to one of the two classes. The model is trained on after which it is present with and is asked to predict the label of this previously unseen data point.
The prediction function will be denoted by . The output of a prediction will be denoted by . SVM is a description of such a model and how can one optimize given a dataset and a loss function.
SVM’s goal is to construct a prediction function which will represent a hyperplane that can be used to divide the space into two parts. One SVM model is considered to be better than a different SVM model for the same dataset if the margin (distance) between the hyperplane and the nearest data point is maximized. The nearest data point to the hyperplane is called the support vector. Therefore we have a clear metric to optimize.
.svg/1920px-Svm_separating_hyperplanes_(SVG).svg.png)
Recall the general equation of a hyperplane: where denotes a normal vector to the hyperplane and is the offset ( determines the offset from the origin along the normal vector ). Since our goal is the find the optimal hyperplane, we end up with trainable parameters (). Once the hyperplane is found we can construct two additional parallel hyperplanes which reside at the support vectors of the two classes, and . Then, all points from the dataset adhere to the following
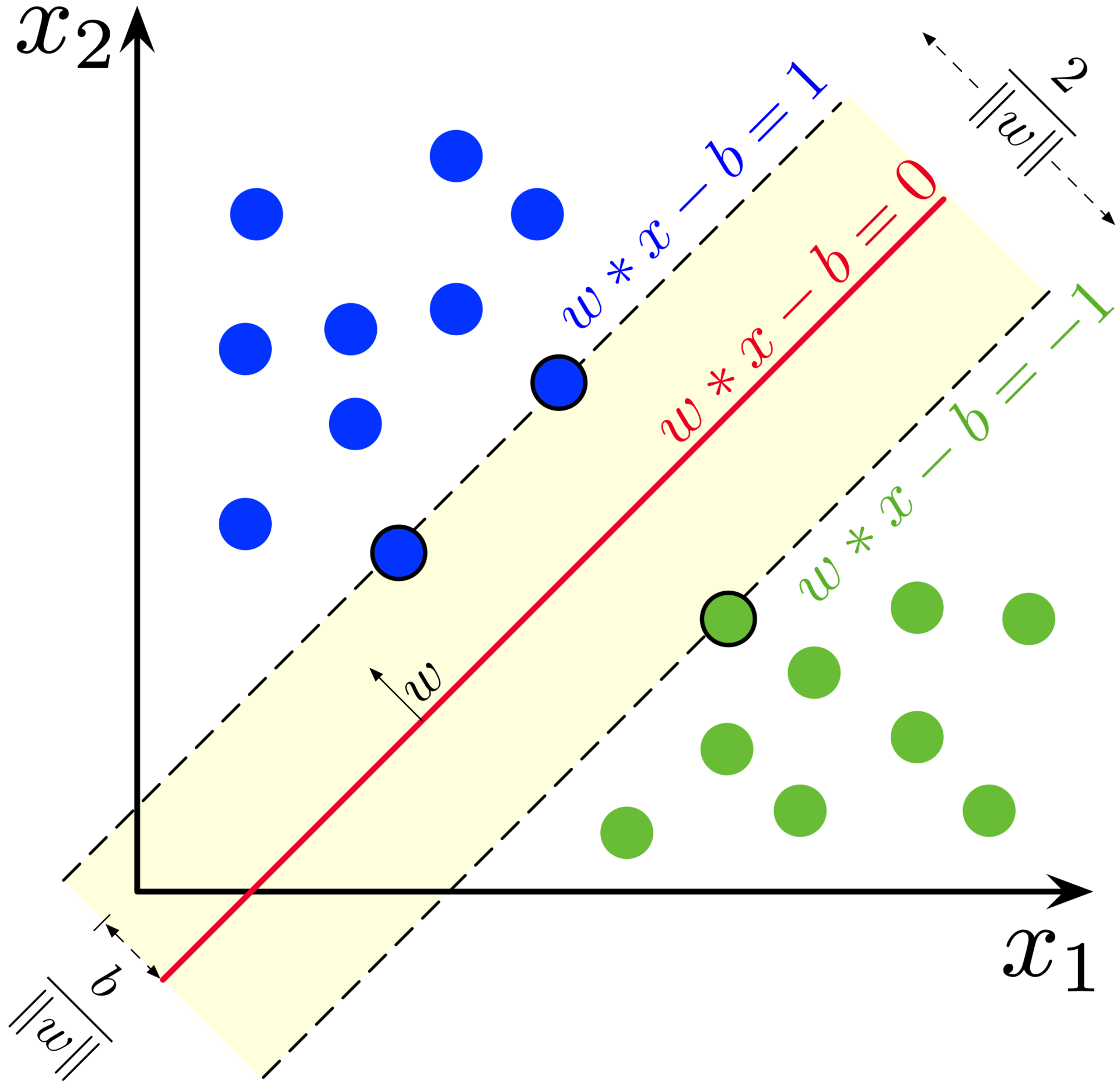
Since is the margin and we want to maximize it, the problem can be restated as a minimization problem of . Our predictor can be neatly expressed as with an edge case of when lies perfectly on the hyperplane, then we can just assume that belongs to one of the two classes. This is called a hard-margin SVM since it works only for perfect datasets which do not have outliers.
Now that we have the model we need to introduce a way to train it. There are many techniques to do so. Here we will focus on one which uses gradient descent. Firstly, we need some function we want to optimize. We will use the hinge function which will suit our needs well: . Notice, that when the guess is correct, then as shown before, thus . If the guess is incorrect, . So if for every data point then we have found a hyperplane that divides the space correctly. Hinge loss introduces a soft-margin since it allows for misclassification with a quantifiable result. We also have to incorporate the minimization of as previously stated. Finally, we can define a loss function over the whole dataset which we will want to minimize:
Here is the regularization hyperparameter controlling the trade-off between correct predictions and large margins. To perform gradient descent we will need to compute the partial derivatives with respect to the trainable parameters ( and ). Sadly the hinge function is not differentiable, but we can consider it by splitting it into two cases: when we reach the left and right case of the function.
Which yields the following gradient (recall that is a vector):
For each training example from our dataset we can now first check the condition. We can perform gradient descent with the gradient specified above and conditionally apply a different gradient based on the condition. Since the gradient points to the steepest ascent and our task is to minimize the function, we will subtract the gradient instead of adding it. Our parameters will now converge iteratively, where is the iteration number for each :
See linear_soft_margin_svm.jl for a practical implementation of the so far introduced concepts
So far we have been generating hyperplanes which intrinsically suffer from being able to classify only linearly separable datasets. For instance, the XOR function is not linearly separable. To solve non-linear problems one has to introduce non-linearity to the model, similarly to how neural networks use non-linear activation functions. One such way would be to introduce extra dimensions where the dataset can be divided by a hyperplane. If is the space of the data points, we want to find such a mapping, called feature map, for some (preferably since we want to increase the dimensionality) together with a kernel function
Since we are operating in the euclidean space with the dot product as the inner product space, we can rewrite as . Direct computation of is not needed, we will only need to find the kernel function. This kernel function will replace dot products used throughout the SVM method.

Note that if we set then , which gives us the SVM for linearly separable problems. Now, this problem can be expressed as a primal one and proceed with gradient descent as we did for the linear case. However, for some not precisely known reason the literature about SVMs has converged towards solving it as a Lagrangian dual and, as O. Chapelle (2007) argues, the primal one can provide many advantages. In both the primal and dual problem formulation is never directly computed, it is always used indirectly through the kernel function. So, to not diverge from literature I will present the dual problem which requires Quadratic Optimization instead of gradient descent.
To start we introduce the Lagrange primal which we want to minimize on and
subject to . This is not enough since we want to get rid of the . Thus we attempt to minimize on and to derive the dual:
Which yields the dual which has to be minimized as
Subject to and . To solve this one has to use quadratic optimization which is well beyond the scope of this document. A popular approach is the SMO algorithm (J. Platt 1998).
In the new space can be expressed as the following linear combination, for support vectors (ie. those with ):
And can be computed from the support vectors as well:
Then we can return to our predictor function
Many kernel function exist and can be used for different use cases. A common choice for a kernel function is the basis radial function, it has a single hyperparameter :
See non_linear_svm.jl for a practical implementation of a SVM with a kernel trained on a non linearly separable dataset.
If the amount of classes is larger than 2, we can construct multiple SVM and treat them as a single larger SVM. There are many popular techniques for that, but here two most popular approaches will be mentioned. Let there be classes.
- one-versus-all: we construct SVMs trained to treat the dataset as having two classes: one for the target class, and the other for all other classes. To then perform predictions, we can run the new point through all SVMs and see which one is the most certain about its prediction. Note, that the definition of the prediction function had a co-domain of so it is not possible to decide which SVM is the most certain. Therefore the prediction function has to be altered to produce quantifiable scores.
- one-versus-one: we construct SVMs for every combination of pairs of classes. Then to perform predictions, we run all SVMs and collect votes. The class with most votes wins.
In the case of one-versus-all the prediction function has to be reformulated unlike in the one-versus-one case. However, one-versus-one comes with a quadratic amount of SVMs unlike the linear one for one-versus-all. Thus the one-versus-one approach will scale horribly for larger values of .
See multiclass_svm.jl for a practical implementation of a multiclass SVM using the one-versus-all approach.
- All images taken from the well-written Wikipedia article on SVMs https://en.wikipedia.org/wiki/Support_vector_machine
- V. Vapnik, Statistical Learning Theory (1998)
- O. Chapelle, Training a Support Vector Machine in the Primal (2007)
- J. Platt, Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines (1998)